(报告出品方/作者:国信证券,熊莉,张伦可,朱松,库宏垚)
核心观点:
人工智慧作为第四次科技革命,已经进入2.0时代。人工智慧概念於1956年被提出,AI产业的第一轮爆发源自2012年,2012年AlexNet模 型问世开启了CNN在图像识别的应用,2015年机器识别图像的准确率首次超过人(错误率低於4%),开启了计算机视觉技术在各行各业 的应用。但是,人工智慧1.0时代面临着模型碎片化,AI泛化能力不足等问题。2017年Google Brain团队提出Transformer架构,奠定了 大模型领域的主流演算法基础,从2018年开始大模型迅速流行,2018年谷歌团队的模型参数首次过亿,到2022年模型参数达到5400亿,模 型参数呈现指数级增长,「预训练 微调」的大模型有效解决了1.0时代AI泛化能力不足的问题。新一代AI技术有望开始全新一轮的技术 创新周期。
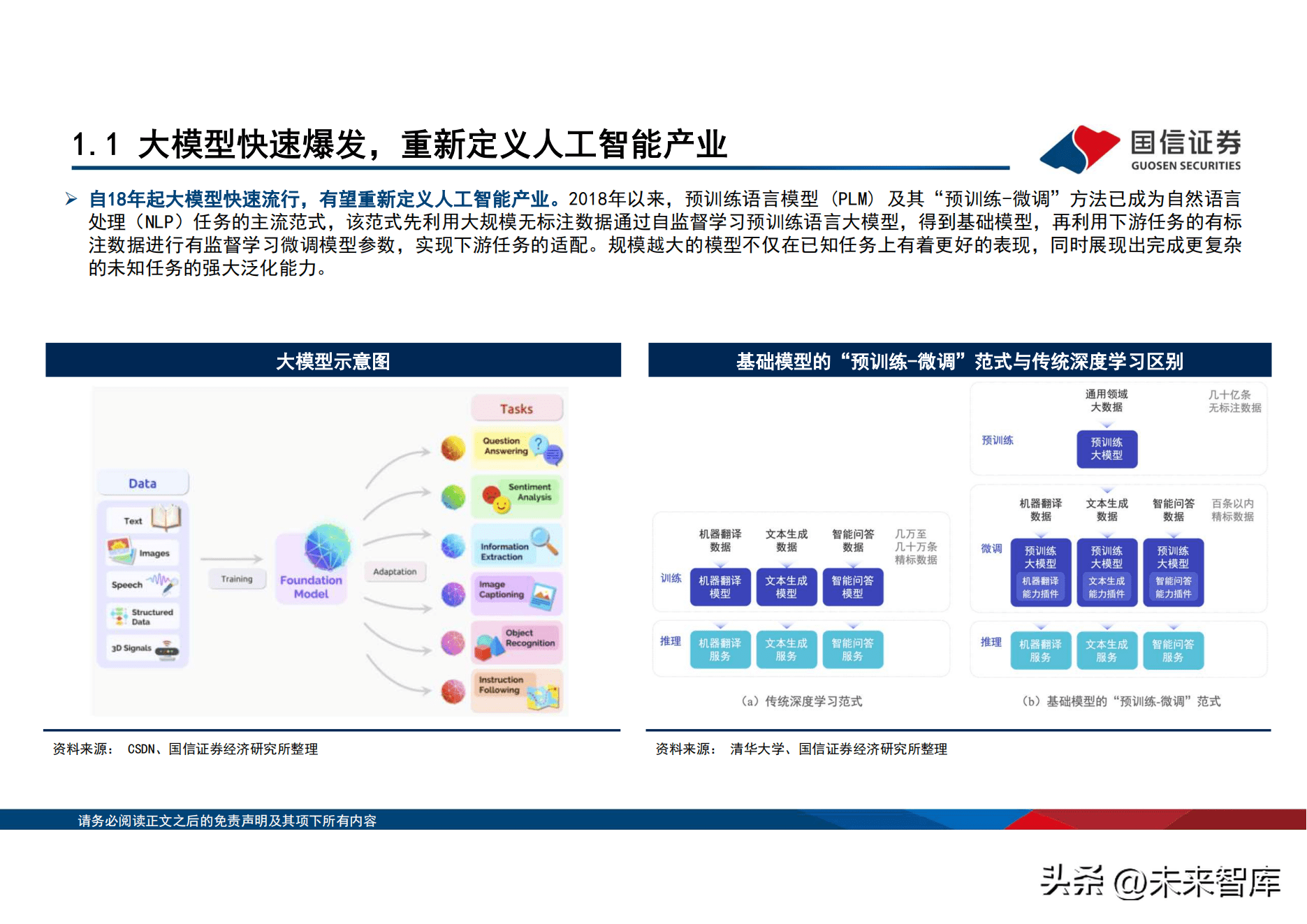
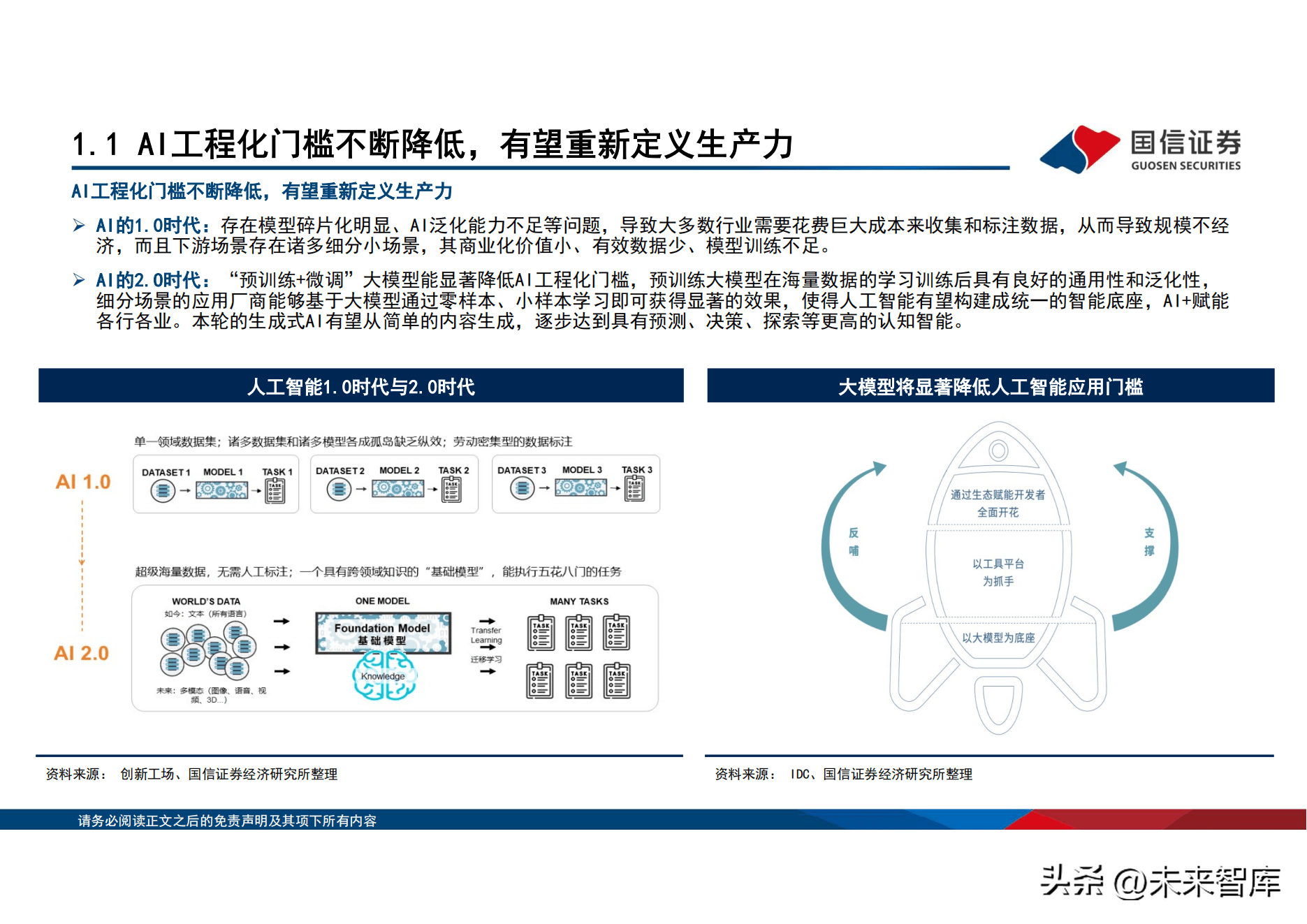
自18年起大模型快速流行,有望重新定义生产力。2018年以来,预训练语言模型 (PLM) 及其「预训练-微调」方法已成为自然语言处理 (NLP)任务的主流范式,该范式先利用大规模无标注数据通过自监督学习预训练语言大模型,得到基础模型,再利用下游任务的有标 注数据进行有监督学习微调模型参数,实现下游任务的适配。在AI的1.0时代:存在模型碎片化明显、AI泛化能力不足等问题。「预训 练 微调」大模型能显着降低AI工程化门槛,预训练大模型在海量数据的学习训练後具有良好的通用性和泛化性,细分场景的应用厂商 能够基於大模型通过零样本、小样本学习即可获得显着的效果,使得人工智慧有望构建成统一的智能底座,AI 赋能各行各业。本轮的 生成式AI有望从简单的内容生成,逐步达到具有预测、决策、探索等更高的认知智能。
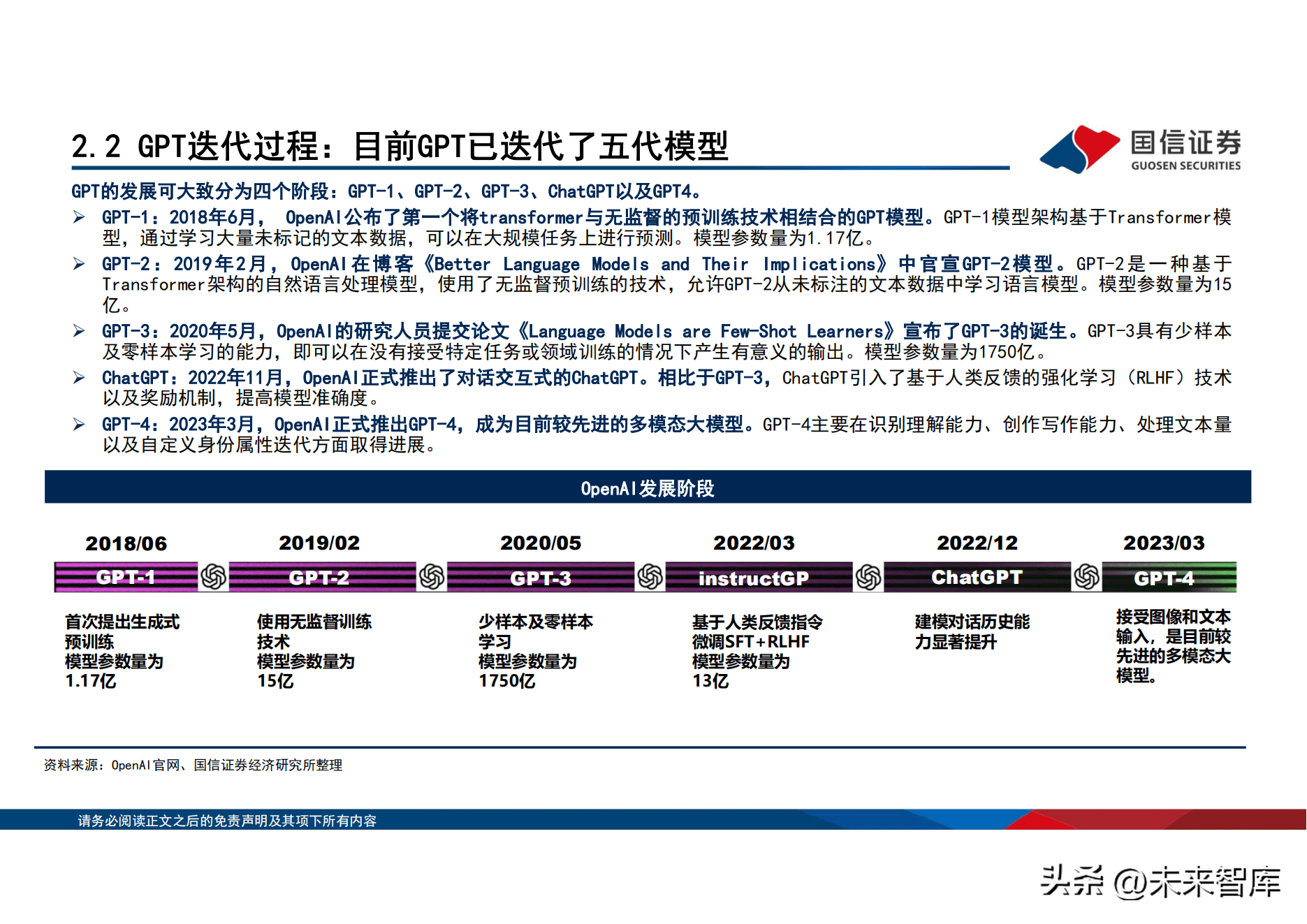
OpenAI当前已迭代五代模型,GPT-4开始布局多模态。OpenAI於2015年成立,微软於2019年开始与OpenAI建立战略合作夥伴关系,GPT共 发布五代模型GPT-1、GPT-2、GPT-3、ChatGPT以及GPT4。GPT-1於2018年6月发布,首次将transformer与无监督的预训练技术相结合。 2020年5月发布GPT-3,模型参数量为1750亿。2022年11月,OpenAI正式推出了对话互动式的ChatGPT。相比於GPT-3,ChatGPT引入了基 於人类反馈的强化学习(RLHF)技术以及奖励机制。2023年3月,OpenAI正式推出GPT-4,成为目前较先进的多模态大模型。GPT-4主要 在识别理解能力、创作写作能力、处理文本量以及自定义身份属性迭代方面取得进展。
百度於2023年3月正式推出大模型文心一言。文心一言主要由文心大模型提供支持,文心一言拥有有监督精调、RLHF、提示构建、知识增 强、检索增强和对话增强六大核心技术。其中前三项与ChatGPT的技术十分类似,知识增强包括知识内化和知识外用;检索增强指基於 百度搜索引擎,先对内容进行检索,再筛选出有用的部分整合输出结果;对话增强指记忆机制、上下文理解和对话规划等技术。
01、行业梳理:生成式AI有望带动新一轮技术创新周期
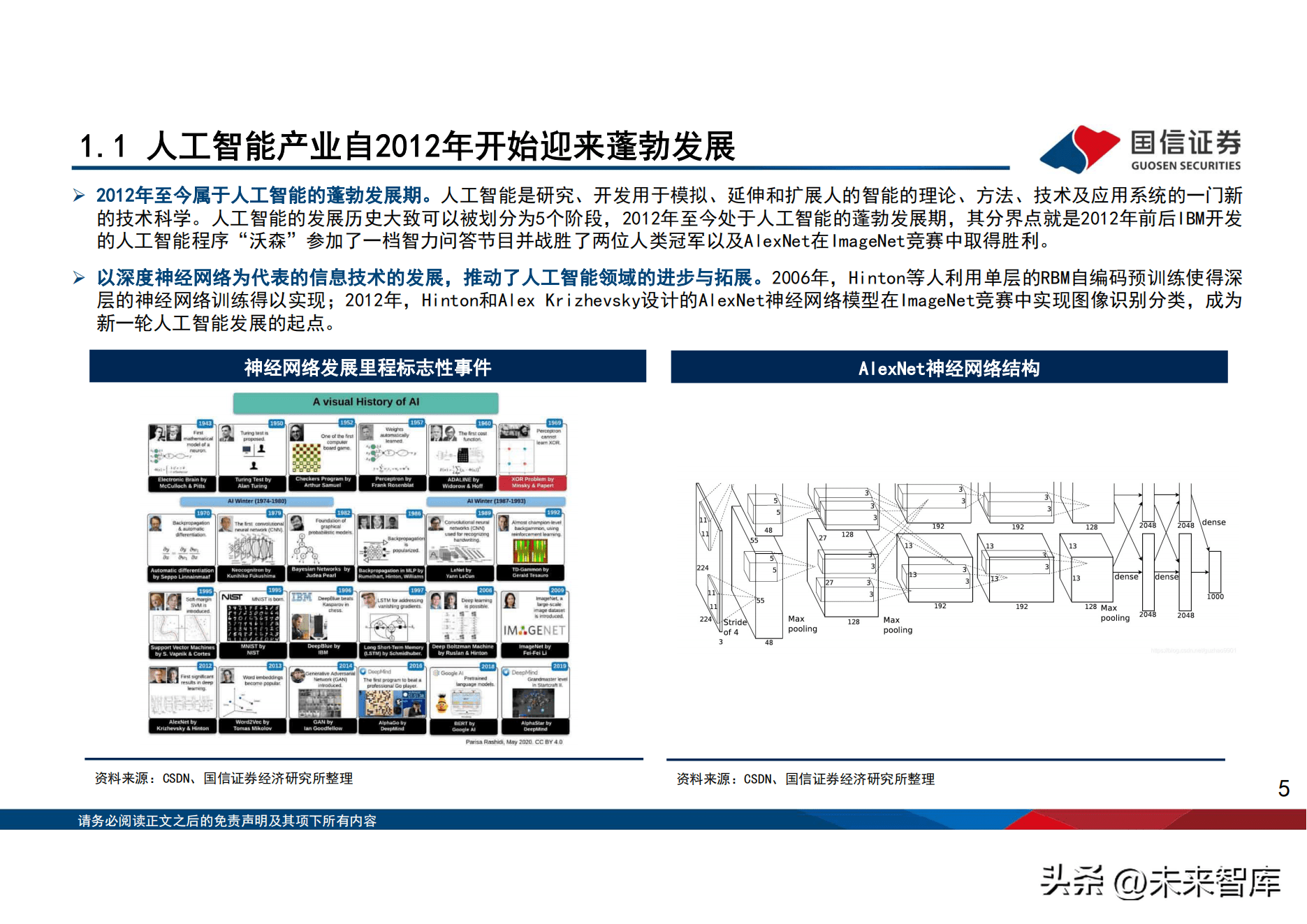
1.1、人工智慧产业自2012年开始迎来蓬勃发展
2012年至今属於人工智慧的蓬勃发展期。人工智慧是研究、开发用於模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新 的技术科学。人工智慧的发展历史大致可以被划分为5个阶段,2012年至今处於人工智慧的蓬勃发展期,其分界点就是2012年前後IBM开发 的人工智慧程序「沃森」参加了一档智力问答节目并战胜了两位人类冠军以及AlexNet在ImageNet竞赛中取得胜利。 以深度神经网路为代表的信息技术的发展,推动了人工智慧领域的进步与拓展。2006年,Hinton等人利用单层的RBM自编码预训练使得深 层的神经网路训练得以实现;2012年,Hinton和Alex Krizhevsky设计的AlexNet神经网路模型在ImageNet竞赛中实现图像识别分类,成为 新一轮人工智慧发展的起点。
人工智慧1.0时代(2012年-2018年):人工智慧概念於1956年被提出,AI产业的第一轮爆发源自2012年,2012年AlexNet模型问世开启 了CNN在图像识别的应用,2015年机器识别图像的准确率首次超过人(错误率低於4%),开启了计算机视觉技术在各行各业的应用,带 动了人工智慧1.0时代的创新周期,AI 开始赋能各行各业,带动效率提升。但是,人工智慧1.0时代面临着模型碎片化,AI泛化能力不 足等问题。 人工智慧2.0时代(2017年-至今):2017年Google Brain团队提出Transformer架构,奠定了大模型领域的主流演算法基础,从2018年开 始大模型迅速流行,2018年谷歌团队的模型参数首次过亿,到2022年模型参数达到5400亿,模型参数呈现指数级增长,「预训练 微调」 的大模型有效解决了1.0时代AI泛化能力不足的问题。新一代AI技术有望开始全新一轮的技术创新周期。
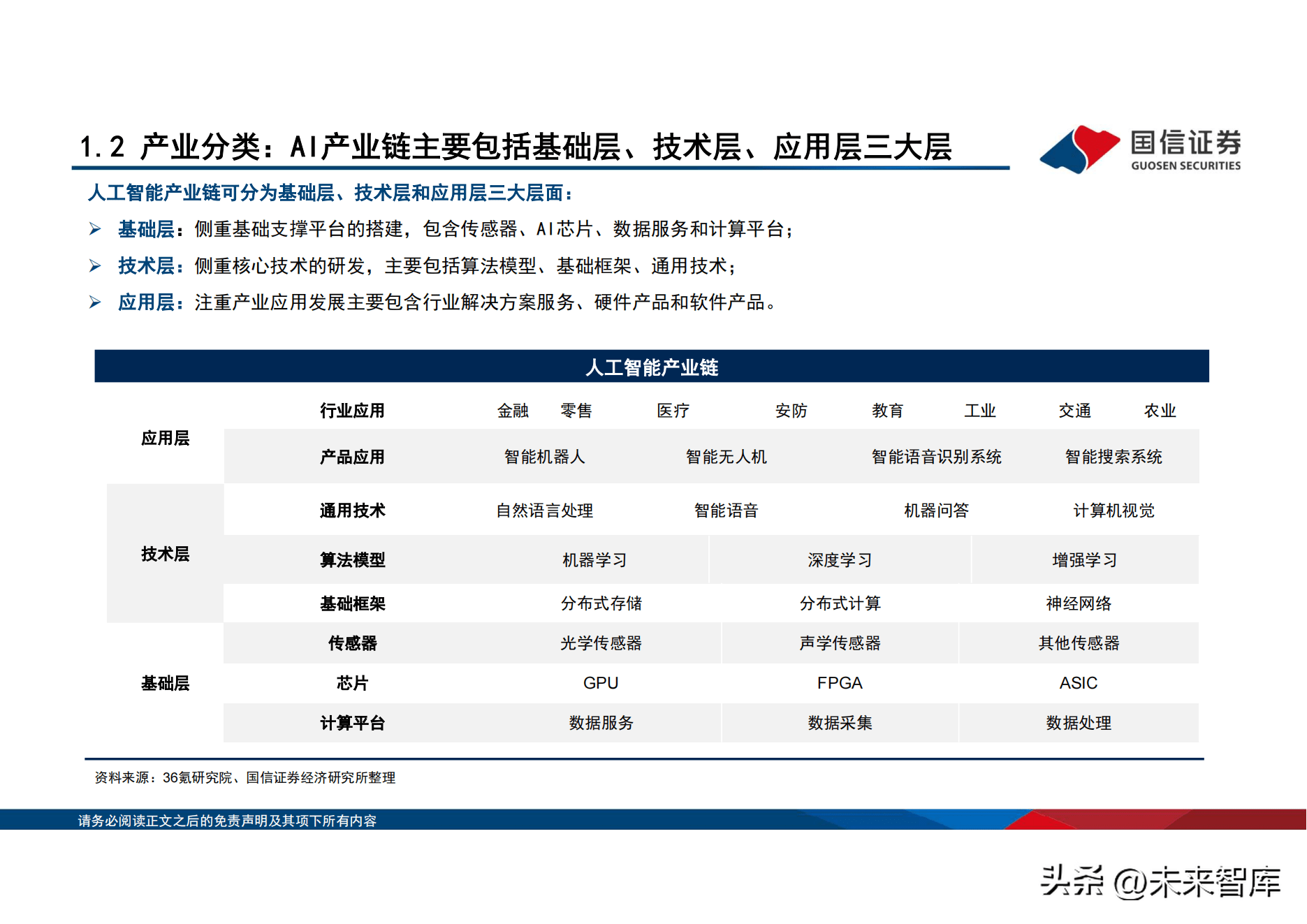
1.2、产业分类:AI产业链主要包括基础层、技术层、应用层三大层
人工智慧产业链可分为基础层、技术层和应用层三大层面: 基础层:侧重基础支撑平台的搭建,包含感测器、AI晶元、数据服务和计算平台; 技术层:侧重核心技术的研发,主要包括演算法模型、基础框架、通用技术; 应用层:注重产业应用发展主要包含行业解决方案服务、硬体产品和软体产品。
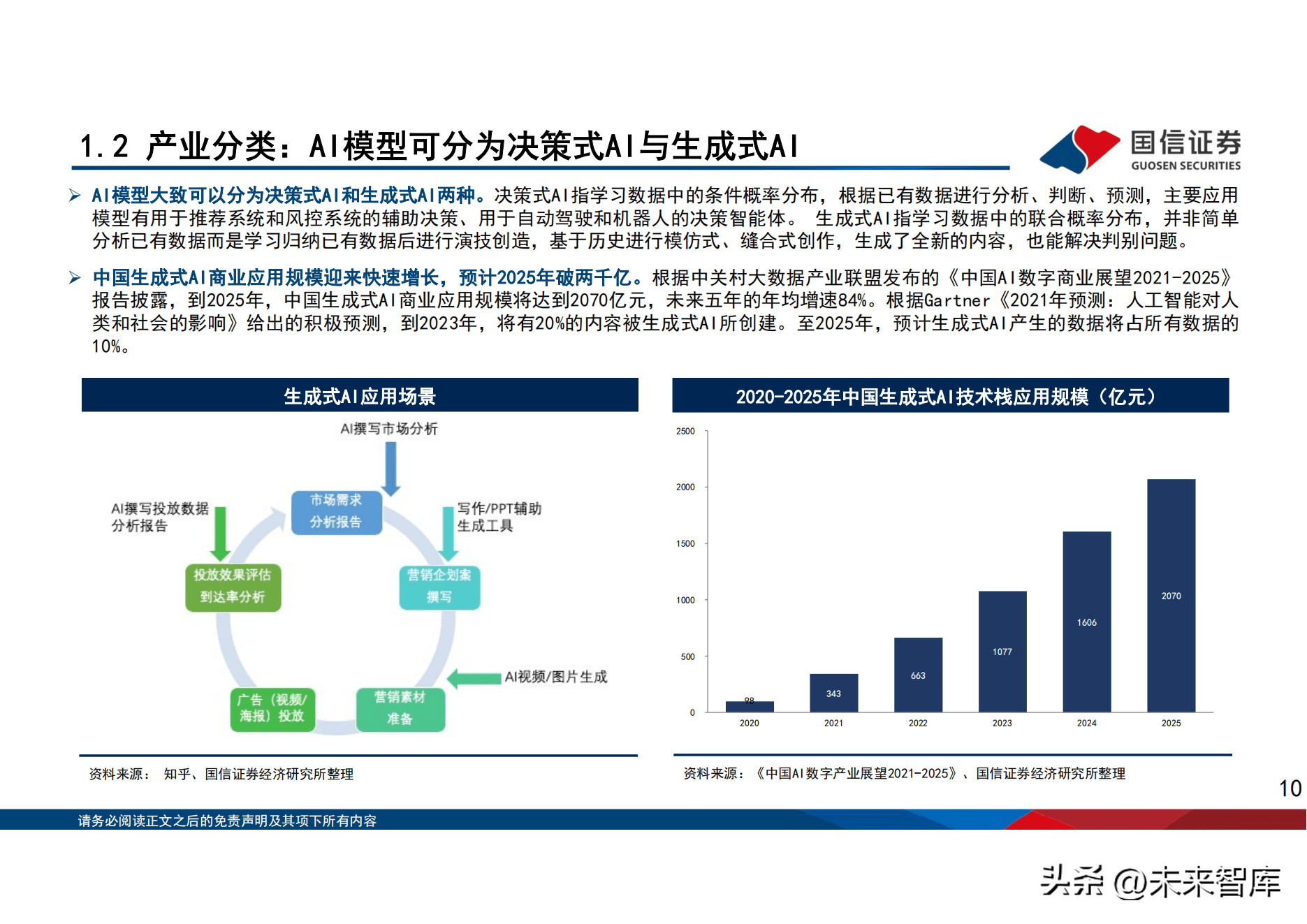
AI模型大致可以分为决策式AI和生成式AI两种。决策式AI指学习数据中的条件概率分布,根据已有数据进行分析、判断、预测,主要应用 模型有用於推荐系统和风控系统的辅助决策、用於自动驾驶和机器人的决策智能体。 生成式AI指学习数据中的联合概率分布,并非简单 分析已有数据而是学习归纳已有数据後进行演技创造,基於历史进行模仿式、缝合式创作,生成了全新的内容,也能解决判别问题。
中国生成式AI商业应用规模迎来快速增长,预计2025年破两千亿。根据中关村大数据产业联盟发布的《中国AI数字商业展望2021-2025》 报告披露,到2025年,中国生成式AI商业应用规模将达到2070亿元,未来五年的年均增速84%。根据Gartner《2021年预测:人工智慧对人 类和社会的影响》给出的积极预测,到2023年,将有20%的内容被生成式AI所创建。至2025年,预计生成式AI产生的数据将占所有数据的 10%。
1.3、AI产业正在逐渐从传统分析型AI走向生成式AI
人工智慧在经历前期技术积累和迭代後,逐渐突破传统分析型AI领域,迎来生成式AI的爆发期。从2012年至今,生成式AI急速发展,其 源头就是DNN演算法的升级,实现了语音和图像识别等功能。 生成式AI市场前景广阔,赛道内诞生多家独角兽企业。据波士顿谘询预测,至2025年生成式人工智慧的市场规模将至少达到600亿美元, 而其中大约30%的AI应用将来自广义的生成式AI技术。随着生成式AI模型的进一步完善,自主创作和内容生产的门槛将大大降低,市场 响应该领域的巨大需求,在2019-2022年间共有7家独角兽公司诞生,截至2023年2月,这七家的估值合计达到644亿美元,其中OpenAI借 助旗下产品ChatGPT爆火的东风,一家公司的估值便突破290亿美元。
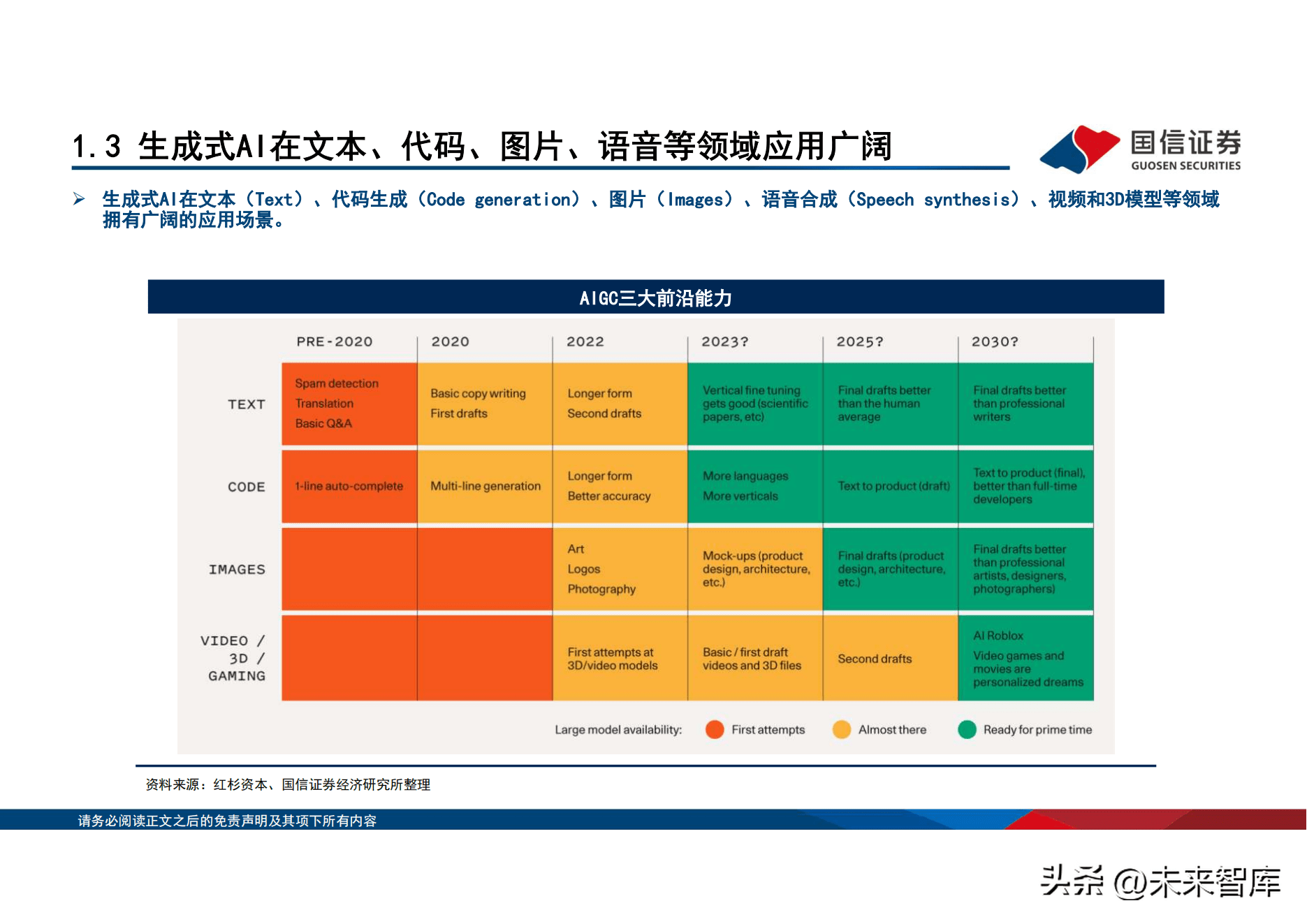
AIGC具备三大前沿能力,未来应用空间广阔。AIGC发展火热,以chatgpt为代表的问答机器人,逐步走向大众视野。AIGC(AIGenerated Content)即人工智慧生产内容,可用於代码生成、文本问答、图像生成等。AIGC是继专业生成内容(PGC)和用户生成内容 (UGC)之後,利用人工智慧技术生成内容的新生产方式。AIGC技术演化出三大前沿技术能力:数字内容孪生、数字内容的智能编辑、 数字内容的智能创作。ChatGPT能理解并生成文字,属於AIGC技术应用中的文本生成模态应用模型。根据Gartner测算,当前AIGC占所有 生成数据小於1%,AIGC生成数据渗透率有广阔提升空间,预计该数字到2025年或上升至10%。
AIGC产业链上游主要提供AI技术及基础设施,包括数据供给方、数据分析及标注、创造者生态层、相关演算法等。AIGC应用对数字基础设 施要求较高,随着ChatGPT掀起AIGC发展浪潮,数据基础设施有望加速升级。中游主要针对文字、图像、视频等垂直赛道,提供数据开 发及管理工具,包括内容设计、运营增效、数据梳理等服务。下游包括内容终端市场、内容服务及分发平台、各类数字素材以及智能设 备,AIGC内容检测等。
02、海外玩家:OpenAI持续领先,谷歌等巨头纷纷布局
2.1、OpenAI发展历程
OpenAI的发展历程分为四个阶段: 阶段一:2015年OpenAI首席执行官阿尔特曼,与埃隆·马斯克等人宣布出资10亿美元,创立了非营利性研究机构OpenAI。 阶段二:2019年OpenAI的架构进行了调整,调整後变身为两家机构——营利性机构OpenAI LP和最初的非营利机构OpenAI,Inc。 阶段三:从2019年开始,微软与OpenAI建立了战略合作夥伴关系,不少於三次投资,共投入130亿美元,成为OpenAI最大的有限合伙人。 OpenAI LP从成立之初参与投资的VC,也成为有限合伙人。
阶段四:在OpenAI未来盈利後,逐步回报投资人:1、优先保证OpenAI的首批投资者收回初始资本;2、微软投资完成、OpenAI LP首批 投资人收回初始投资後,微软有权获得OpenAI LP 75%利润;3、微软收回130亿美元投资、从OpenAI LP获得920亿美元利润後,它分享 利润的比例从75%降到49%;4、OpenAI LP产生的利润达到1500亿美元後,微软和其他风险投资者的股份将无偿转让给OpenAI LP的普通 合伙人——非营利机构OpenAI, Inc。
自2013年起人工智慧迎来发展高潮。2006年Hinton提出「深度学习」神经网路使得人工智慧性能获得突破性进展,在2013年深度学习宣 发在语音和视觉识别上取得成功,识别率分别超过99%和95%,人工智慧进入感知智能时代。在此期间全球人工智慧市场保持高速增长, 截至2015年全球AI市场规模达到74.5亿美元,而且愈发受到投资机构青睐,投资额从2012年的0.62亿元提升至2015年的142.3亿美元, 增长幅度达到2195.16%。2015年OpenAI作为一家非营利性人工智慧研究公司创立。基於人工智慧高速发展的背景,Openai由Elon Musk,Sam Altman(美国创业孵化器总裁)及Pieter Abbeel(PayPal联合创始人)等人创建,在创立之初由Elon Musk和Sam Altman担任其联合主席,由Pieter Abbeel等人担任顾问。
2016年4月,OpenAI发布了第一个项目——OpenAI Gym Beta。OpenAI Gym是由OpenAI开发的一个开源平台,旨在在各种强化学习问题中 加速演算法的开发和比较,该工具也是OpenAI第一个开放的成果。 Gym的核心组件是环境(Environment)和智能体(Agent)。环境是一个可观察到的系统,它定义了智能体如何与外部世界交互;智能 体则是一个能够感知到和影响环境的程序,是训练和优化的对象。 Gym提供了许多强化学习问题的标准化环境。例如经典控制问题(Classic control),Atari游戏,甚至是Roboschool等物理模拟环境。
2017年7月,OpenAI公布最新强化学习演算法PPO(Proximal Policy Optimization),好於同期最强的演算法模型,成为openai默认的强化 学习演算法。PPO包含三方面的技术进步: 1.代理策略和价值函数的优化,在 PPO演算法中,同时优化代理策略和价值函数( Value Function),通过在最大化奖励的同时最大化代理策略和价值函数的梯度,同时对这两者进行优化;2.剪辑代理策略更新是PPO演算法的 核心部分,该方法通过使用约束优化来保证新的策略不会太远离旧的策略,减轻了过渡调整代理策略的问题,并提高总体稳定性;3.优 化函数的选择,在PPO演算法中,需要选择合适的优化函数来最大化代理策略和价值函数的梯度,常用的优化函数包括Adam、SGD和 RMSProp等。
2018年6月, OpenAI公布了第一个将transformer与无监督的预训练技术相结合的GPT模型,其取得的效果要好於当前的已知演算法。该模 型被称为GPT-1,并由一个具有10亿个参数的单层transformer组成。这一模型的训练使用了大规模的无监督语料库,使它能够生成各种 自然语言处理任务的有力表现。同月OpenAI宣布他们的OpenAI Five已经开始在Dota2游戏中击败业余人类团队,OpenAIFive使用了256 个P100 GPUs和128000个CPU核,通过每天玩180年时长的游戏来训练模型。在同年8月份的专业比赛中,OpenAIFive输掉了2场与顶级选 手的比赛,但是比赛的前25-30分钟内,OpenAI Five的模型的有着十分良好的表现。OpenAI Five继续发展并在2019年4月15日宣布打败 了当时的Dota2世界冠军。
2019年2月,OpenAI在博客《Better Language Models and Their Implications》中官宣GPT-2模型。GPT-2模型拥有15亿参数,基於 800万网页数据训练,该模型就是GPT的规模化结果,在10倍以上的数据以10倍以上的参数训练。OpenAI在2月份GPT-2发布的时候仅仅公 开了他们的1.24亿版本的预训练结果,其後的5月份发布了3.55亿参数版本的预训练结果,并在半年後的8月份发布了一个7.74亿参数版 本的GPT-2预训练结果。2019年11月5日,15亿参数的完整版本的GPT-2预训练结果发布。
2019年3月,OpenAI将生成模型开始拓展至其他领域。同年3月4日,OpenAI发布了一个用於强化学习代理的大规模多代理游戏环境: Neural MMO。该平台支持在一个持久的、开放的任务中的存在大量的、可变的agent。4月25日,OpenAI继续公布最新的研究成果: MuseNet,这是一个深度神经网路,可以用10种不同的乐器生成4分钟的音乐作品,并且可以结合多种音乐风格。
2.2、GPT迭代过程:目前GPT已迭代了五代模型
GPT的发展可大致分为四个阶段:GPT-1、GPT-2、GPT-3、ChatGPT以及GPT4。 GPT-1:2018年6月, OpenAI公布了第一个将transformer与无监督的预训练技术相结合的GPT模型。GPT-1模型架构基於Transformer模 型,通过学习大量未标记的文本数据,可以在大规模任务上进行预测。模型参数量为1.17亿。 GPT-2: 2019年 2月, OpenAI在博客《Better Language Models and Their Implications》中官宣 GPT-2模型。GPT-2是一种基於 Transformer架构的自然语言处理模型,使用了无监督预训练的技术,允许GPT-2从未标注的文本数据中学习语言模型。模型参数量为15 亿。
GPT-3:2020年5月,OpenAI的研究人员提交论文《Language Models are Few-Shot Learners》宣布了GPT-3的诞生。GPT-3具有少样本 及零样本学习的能力,即可以在没有接受特定任务或领域训练的情况下产生有意义的输出。模型参数量为1750亿。 ChatGPT:2022年11月,OpenAI正式推出了对话互动式的ChatGPT。相比於GPT-3,ChatGPT引入了基於人类反馈的强化学习(RLHF)技术 以及奖励机制,提高模型准确度。 GPT-4:2023年3月,OpenAI正式推出GPT-4,成为目前较先进的多模态大模型。GPT-4主要在识别理解能力、创作写作能力、处理文本量 以及自定义身份属性迭代方面取得进展。
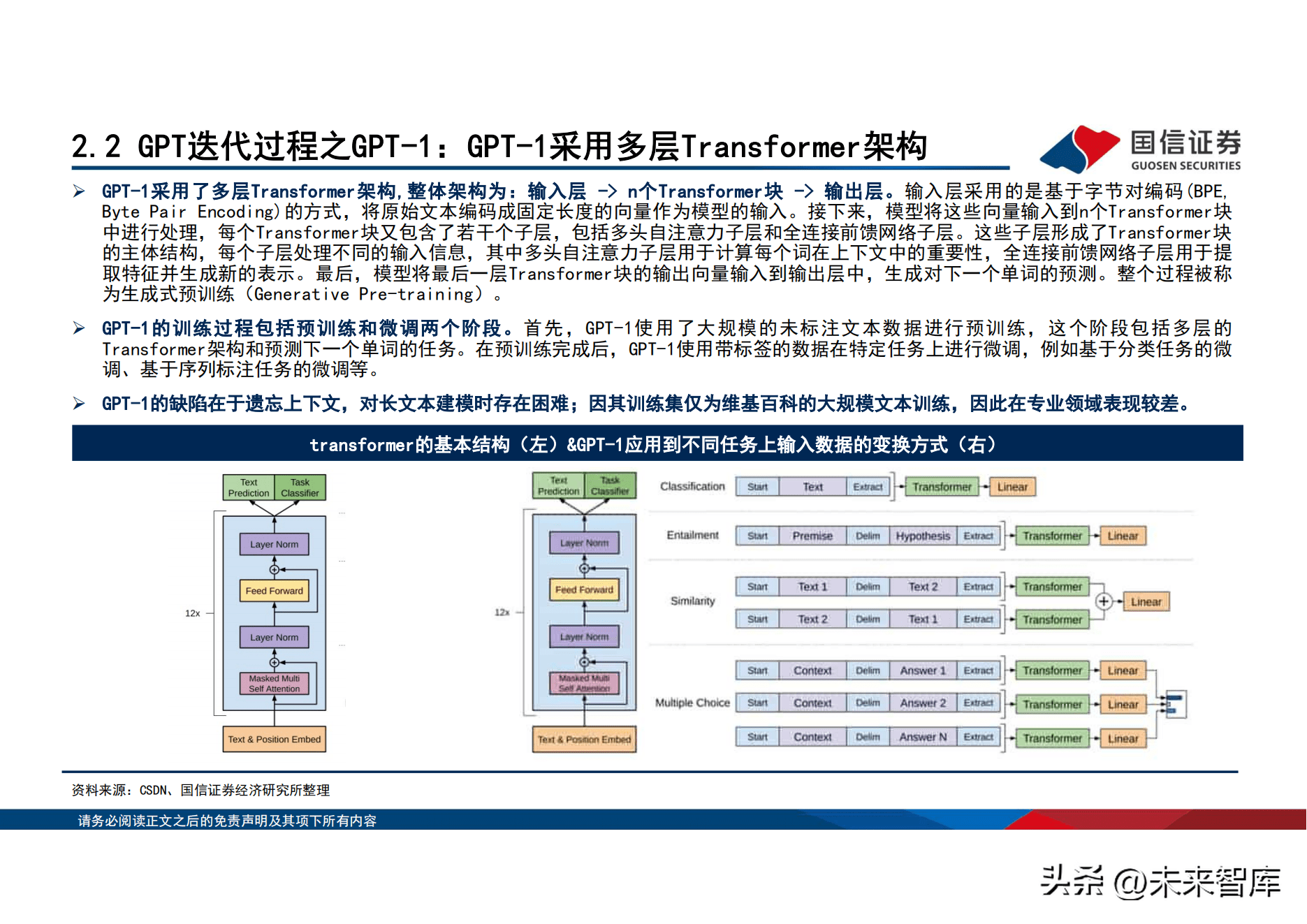
GPT-1采用了多层Transformer架构,整体架构为:输入层 -> n个Transformer块 -> 输出层。输入层采用的是基於位元组对编码(BPE, Byte Pair Encoding)的方式,将原始文本编码成固定长度的向量作为模型的输入。接下来,模型将这些向量输入到n个Transformer块 中进行处理,每个Transformer块又包含了若干个子层,包括多头自注意力子层和全连接前馈网路子层。这些子层形成了Transformer块 的主体结构,每个子层处理不同的输入信息,其中多头自注意力子层用於计算每个词在上下文中的重要性,全连接前馈网路子层用於提 取特徵并生成新的表示。最後,模型将最後一层Transformer块的输出向量输入到输出层中,生成对下一个单词的预测。整个过程被称 为生成式预训练(Generative Pre-training)。
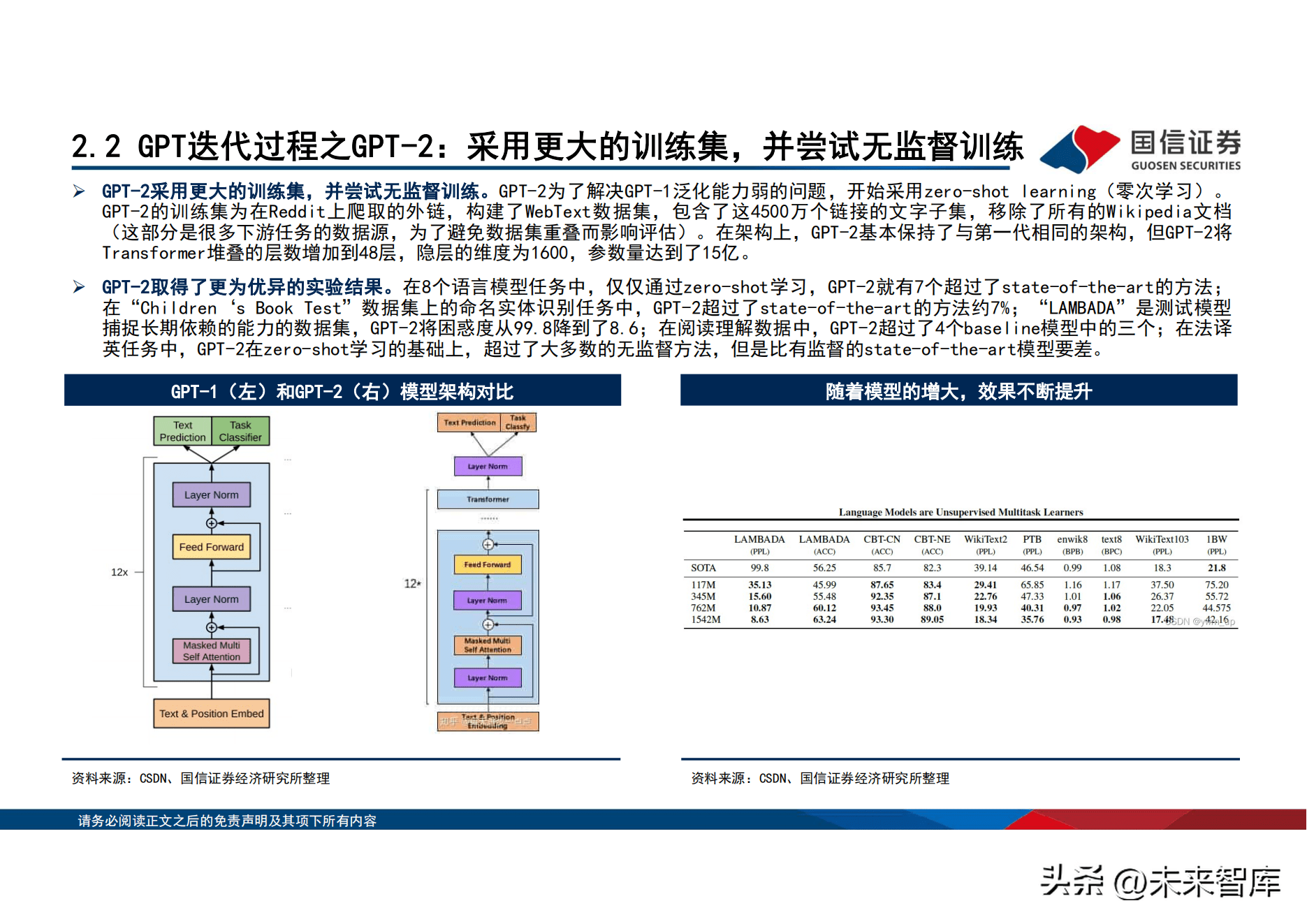
GPT-2采用更大的训练集,并尝试无监督训练。GPT-2为了解决GPT-1泛化能力弱的问题,开始采用zero-shot learning(零次学习)。 GPT-2的训练集为在Reddit上爬取的外链,构建了WebText数据集,包含了这4500万个链接的文字子集,移除了所有的Wikipedia文档 (这部分是很多下游任务的数据源,为了避免数据集重叠而影响评估)。在架构上,GPT-2基本保持了与第一代相同的架构,但GPT-2将 Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量达到了15亿。
GPT-2取得了更为优异的实验结果。在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法; 在「Children『s Book Test」数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;「LAMBADA」是测试模型 捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;在法译 英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差。
GPT-4可以接受文本和图像形式的输入,新能力与纯文本设置并行,允许用户指定任何视觉或语言任务。具体来说,GPT-4在人类给定由 散布的文本和图像组成的输入的情况下生成相应的文本输出(自然语言、代码等)。在一系列领域——包括带有文本和照片的文档、图 表或屏幕截图上,GPT-4展示了与纯文本输入类似的功能。此外,它还可以通过为纯文本语言模型开发的测试时间技术得到增强,包括 少样本和思维链。实际应用方面,OpenAI官网给出了7个视觉输入例子:1、描述多张图片内容,发现不合常理之处;2、根据图表,推 理作答;3、看图考试;4、简练指出图片的违和之处;5、阅读论文,总结摘要与解释图表;6、解读人类梗图;7、理解漫画含义。
GPT-4在真实性和有效性方面取得了突破级成果。GPT-4基於对抗性测试程序和ChatGPT得到的经验教训,对模型进行训练运行,当有问 题出现时,基础模型可以以多种方式响应,为了得到用户想要的答案,再使用RLHF对结果进行微调。
2.3、海外玩家之谷歌:谷歌大模型早期发展
2014年1月26日Google收购Deepmind。该事件成为谷歌人工智慧新一阶段起点,之後由Deepmind开发的Alphago於2016年战胜人类世界围 棋冠军。 2017年谷歌发布开源的神经网路架构Transformer模型。该模型首次在「Attention is all you need」一文中提出,在论文中该模型主 要是被用於克服机器翻译任务中传统网路训练时间过长,难以较好实现并行计算的问题,後来,由於该方法在语序特徵的提取效果由於 传统的RNN、LSTM而被逐渐应用至各个领域。 2018年10月,谷歌发布Bert。该大模型基於Transformer架构,在斯坦福大学机器阅读理解水平测试SQuAD1.1中,Bert在全部两个衡量 指标上,全面超越人类表现。同年OpenAI发布GPT-1,同样基於Transformer架构。
2021年5月18日谷歌在谷歌I/O大会发布LaMDA大模型。LaMDA的全称LanguageModel for Dialogue Applications,是一种能力强大的语 言模型,适用於对话应用程序。 LaMDA经过两阶段训练:预训练和微调,在预训练阶段,谷歌首先从公共对话数据和其他公共网页文档 中收集并创建了一个具有1.56T单词的数据集;在微调阶段,谷歌训练 LaMDA,执行混合生成任务以生成对给定上下文的自然语言响应, 执行关於响应是否安全和高质量的分类任务,最终生成一个两种任务都能做的多任务模型。 2021年5月18日谷歌在谷歌I/O大会发布多任务统一模型MUM。MUM不仅可以理解语言,而且可以生成语言;MUM 同时用 75 种不同的语言 进行了多项任务的训练,使其比以前的模型更全面地理解信息;MUM是多模态的,能够理解文本和图像中的信息。
2023年2月6日,谷歌宣布发布Bard新对话式人工智慧技术应用。Bard由谷歌的大型语言模型LaMDA,即对话应用程序语言模型提供支持。 2023年3月21日,谷歌正式宣布开放Bard的访问许可权。Bard采用了先进的深度学习演算法,具有包括翻译、摘要等在内的一系列能力,并 由大量文本提供支持。与ChatGPT相比,从功能来看,ChatGPT通晓多种语言,而Bard暂时只能进行英文对话;从编程能力来看, ChatGPT能生成大段可用的代码,但Bard的这一功能暂不可用;在生成内容的形式方面,ChatGPT一次只能作出一个回应,而Bard一次性 创建几个不同的版本,供用户从中择优选用。
03、中国玩家:百度发布文心一言,中国玩家快速追赶
3.1、百度:正式发布文心一言
2023年3月20日,百度正式推出百度版ChatGPT——文心一言。其发布时间线:2月7日官宣;13日确认将在3月亮相;截至15日有超百家企业 接入;17日在2023 AI 工业互联网高峰论坛上宣布,将通过百度智能云对外提供服务,率先在内容和信息相关的行业和场景落地;22日,李 彦宏在财报信中表示,计划将多项主流业务与文心一言整合;28日,文心一言新闻发布会定档。 文心一言目前主要展现出五大功能,并带来三大产业机会。其功能主要包括:(1)文学创作、(2)商业文案创作、(3)数理逻辑推算、 (4)中文理解、(5)多模态生成。发布会上李彦宏提出AI时代三大产业机会包括:新兴云计算——MaaS模型即服务;行业模型精调——工 业、金融、交通、能源、媒体等;应用开发——文字、图像、音视频生成、数字人、3D生成等。
文心一言主要由文心大模型提供支持。百度文心NLP大模型主要经历了三条主线的发展:第一、文心ERNIE 3.0以及文心·ERNIE 3.0 Titan 模型,在SuperGLUE和GLUE都超过了人类排名第一的水平;第二、文心ERNIE在跨模态、跨语言以及长文档、图模型等方面取得发展,在多个 榜单尤其是视觉语言相关榜单获得第一;第三、生成式对话大模型文心PLATO推动了对话的连续性。 文心一言拥有有监督精调、RLHF、提示构建、知识增强、检索增强和对话增强六大核心技术。其中前三项与ChatGPT的技术十分类似,知识 增强包括知识内化(将知识「渗透」进模型参数中)和知识外用(指的是模型可以直接使用外部的知识);检索增强指基於百度搜索引擎, 先对内容进行检索,再筛选出有用的部分整合输出结果;对话增强指记忆机制、上下文理解和对话规划等技术。
3.2、国内玩家之阿里:通义大模型打造AI统一底座
2022年9月2日,阿里达摩院发布通义大模型系列。该模型打造了国内首个AI统一底座,并构建了通用与专业模型协同的层次化人工智慧体系, 首次实现模态表示、任务表示、模型结构的统一。通过这种统一学习范式,通义统一底座中的单一M6-OFA模型,在不引入任何新增结构的情况 下,可同时处理图像描述、视觉定位、文生图、视觉蕴含、文档摘要等10余项单模态和跨模态任务,并达到国际领先水平。 2023年3月,阿里达摩院已在AI模型社区「魔搭」ModelScope上线了「文本生成视频大模型」。目前文本生成视频大模型,由文本特徵提取、文 本特徵到视频隐空间扩散模型、视频隐空间到视频视觉空间这3个子网路组成,整体模型参数约17亿,目前仅支持英文输入。扩散模型采用 Unet3D 结构,通过从纯高斯杂讯视频中,迭代去噪的过程,实现视频生成的功能。
3.3、国内玩家之腾讯:依托太极平台,腾讯发布混元大模型
2022年4月,腾讯首次对外披露混元大模型,完整覆盖NLP大模型、CV大模型、多模态大模型及众多领域任务。该模型在广告内容理解、行 业特徵挖掘、文案创意生成等方面具备优势和特色。 混元大模型由太极机器学习平台提供底层支持。2015 年,太极机器学习平台1.0诞生,是腾讯首个涵盖「数据导入-特徵工程-模型训练— 在线服务「全流程的一站式机器学习平台;2019 年,太极平台联合腾讯云,打造了三环境(内网/公有云/私有云)统一的「TI-ONE 机器 学习平台」,将机器学习平台能力输出给公网和私有云用户,太极平台服务腾讯内部业务;2022 年,为了解决「广告模型迭代流程研发 效率」问题,太极广告一站式平台上线,目标将广告模型迭代业务流程通过「上太极」产品化,为广告业务提供端到端的一站式模型研发 体验。
3.4、国内玩家之华为:千亿参数大模型——盘古大模型
2021年4月华为发布「盘古大模型」,目前已经发展出包括基础大模型(L0)、行业大模型(L1)、行业细分场景模型(L2)三大阶段的成 熟体系。该模型基於鹏城云脑 Ⅱ和全场景AI计算框架MindSpore的自动混合并行模式,实现在2048卡算力集群上的大规模分散式训练,是 国产全栈式AI基础设施第一次支持2000亿级超大规模语言模型训练,实现16个下游任务中性能指标优於业界SOTA模型。 ModelArts为华为大模型提供研发的平台支持。ModelArts是一站式开发平台,能够支撑开发者从数据到AI应用的全流程开发过程,包含数 据处理、模型训练、模型管理、模型部署等操作,并且提供AI Gallery功能,能够在市场内与其他开发者分享模型。支持图像分类、物体 检测、视频分析、语音识别、产品推荐、异常检测等多种AI应用场景。
04、市场规模:模型参数不断增加,算力需求快速增长
4.1、全球AI市场到2024年将超六千亿美元,复合增速27%
全球AI市场规模预计到2024年将超六千亿美元,复合增速27%。据沙利文谘询统计,2016-2019年,全球市场规模从593亿美元增长至2019年 1918亿美元,复合增长率约48%,预计2020年到2024年将以27%的年复合增长率继续放量,并在2024年达到6158亿美元。 中国AI市场规模预计到2024年约八千亿人民币,复合增速44%。据沙利文谘询统计,2016-2019年,中国市场规模从329.6亿元增长至1372.4 亿元,复合增长率约61%,显着高於全球整体增速水平,预计2020年到2024年将以44%的年复合增长率继续放量,并在2024年突破7993亿元。
4.2、模型参数不断增长,算力需求持续增加
GPT-1迭代至GPT-3,参数量增大1500倍,预训练参数量扩大9000倍。GPT-1、GPT-2和GPT-3的参数量分别为1.17、15.4和1750亿,预训 练数据量分别为5GB、40GB和45TB。此外在序列长度方面,由初代的512增长至2048,模型层数方面也有数倍增长。 按照计算公式,算力需求与模型参数量呈正相关关系。GPT的算力需求分别发生在访问阶段和训练阶段,访问阶段是指用户在使用GPT时, 因提出问题所造成的算力消耗;训练阶段是指在训练GPT模型时所消耗的算力。访问阶段的算力消耗是衡量chatgpt投入的关键指标,假 设每天租用亚马逊AWS云服务,每天成本为461.28*2315=106.79万美元;在训练阶段,自建IDC:伺服器成本约占数据中心成本30%左右, 为满足当前日常访问需求,前期一次性成本。投入约为2315*19.9/30%=13.26亿美元。
英伟达在GPU领域的强劲实力使其成为HPC需求增长的受益者。目前GPT-3.5在微软AzureAI超算基础设施(英伟达V100GPU组成的高带宽集群) 上训练是因为英伟达在AI和图形处理器方面都达到全球领先的技术水平。考虑到该技术在处理与机器学习、深度学习、人工智慧和数据挖 掘相关的复杂工作负载方面的能力,超大规模数据中心和高性能计算(「HPC」)细分市场对GPU的需求也很高。而「Nvidia A100」GPU — —晶元制造商提供的众多数据中心GPU之一就是这样做的。该技术於 2020 年推出,基於上述Ampere 架构构建,性能比其前代产品高出 20 倍。A100专为支持「数据分析,科学计算和云图形」而设计。还有最近推出的基於Nvidia A100的「HGX AI超级计算机」平台,该平台能够 提供「实现HPC创新的极致性能」。
超速伺服器市场需求助推英伟达逐步替代英特尔。目前全球GPU 架构的伺服器出货量远高於CPU架构的 ,其中英伟达GPU对intel的替代其 实是超速伺服器的替代。在超算,Ai训练里,这类伺服器的增长导致对GPU需求大幅提升,以中国为例,目前国内普通伺服器一年出货量再 200亿美金,增速11%;但是超速伺服器,就是搭载GPU的伺服器,一年出货量大概是50亿美金出头,但是增速是87%。
英伟达立足当下,数据中心业务实现腾飞。2022年下半年,英伟达数据中心业务便实现高速增长超过市场预期,驱动2022年Q3增速比市场 预期高了3亿多,因此结合市场环境,2022Q4数据中心超过游戏占比是预期内的结果。公司2022Q4收入指引是74亿美金,虽然环比预期给出 了4.2%增长,相比单Q3环比9%增速低了一点,但是它因为产品单价还在高位,不排除超预期的可能。
4.3、OpenAI官网点击量不断攀升,当前日活近六千万
截至2023年3月16日ChatGPT日活人数达5800 万。ChatGPT2022年11月30日上线,上线一周获得百万注册用户,成为史上最快到百万用户 的产品;2022年12月,日活用户数突破1000万;2023年3月份ChatGPT日活人数已经突破5000万人。日活用户数的增长会带来算力消耗的线性增长。根据算力消耗的计算假设,每位用户平均每次访问输入的信息为1000字,也就意味着在 用户数增长你的同时,算力需求也会随之线性增长,带来更大的算力缺口。
4.4、模型参数增加 用户规模扩大,当前算力需求缺口庞大
首先计算当前用户规模下,算力需求及成本情况: 第一步,拆解字。「token」是当前语言类模型的数据单位。当前的自回归语言模型是根据 token 来作为单位进行数据处理和计算,分 词(tokenization)就是将句子、段落、文章这类型的长文本分解为以 token 为单位的数据结构,把文本分词後每个词表示成向量进 行模型计算。例如在英文语境下,「happy」可能被分解为「hap」、「-py」两个 token,中文语境下,「我很开心」可以分成「我」, 「很」,「开心」三个token。
第二步,计算A100算力单台售价和租赁价格。以英伟达DGX A1OO伺服器作为计算资源:(1)单台伺服器售价19.9万美元;(2)采用云 服务单天成本约为460美元。英伟达超算GPU系列从旧到新包括P100、V100、A100、H100等,三年迭代一次,一次算力提升3-5倍,最新 的一代H100,专门针对大模型开发,大约能提升算力9倍。按全球主要晶元还是A100,一个DGX伺服器有8个A100系列GPU,AI算力性能为 5PetaFLOP/s,单机最大功率6.5kw,售价19.9万美元;如果租用云服务,在亚马逊 AWS预定一年的A100系列 GPU,有8个A100的AWSP4实 例的平均成本约19.22美元,一天的平均成本约为461.28美元。
第三步,测算1000个字(英语)消耗的计算资源。较常见的Transformer类语言模型在推理过程中每个token的计算成本(以FLOPs为指 标)约为2N,其中N为模型参数数量(20年发布的GPT-3拥有1750亿参数,22年谷歌发布的PaLM拥有5400亿参数,由於并未公布当前 GPT3.5的参数数量,当前假定参数数量为3000亿),假设模型的 FLOPS 利用率约为20%,粗略估计ChatGPT一个1000字(假设约1333个 token,注:在英文语境下,一般1000个token=750个单词)问题需要的算力资源为2*1333*3000亿/20%=4PetaFLOP/S。
第五步,计算自建成本和租赁成本。自建IDC:伺服器成本约占数据中心成本30%左右,为满足当前日常访问需求,前期一次性成本。投 入约为2315*19.9/30%=13.26亿美元。(这个数和目前产业里面得到数基本一致)云服务:假设每天租用亚马逊AWS云服务,每天成本为 461.28*2315=106.79万美元。
OpenAI面临着极为严峻的算力成本问题。随着模型日益增大,OpenAI算力成本显着提高。根据国信计算机国内首发的有关ChatGPT算力 准确测算的报告,当前ChatGPT的前期训练阶段一次性投入为3.99亿美元,而後期访问阶段基於当前5000万日活用户的每日租用伺服器 成本为106.79万美元/日,单是租用成本,每年便达到了3.9亿美元。尽管这个数据看起来似乎对於收入来说依然有可能覆盖,可是随着 GPT-4大模型的到来,参数量和访问量将迎来百倍的增长,加上终端应用的算力消耗,光是对於英伟达的算力投入便能达到120亿美元, 之後的访问阶段的算力消耗和算力成本更是OpenAI完全无法覆盖的数字,约为当前的一万倍(参数量和访问量均为原先的100倍)。所 以OpenAI务必要对模型本身进行精简和优化,以满足未来GPT-4的训练参数量和用户访问量。
4.5、蒸馏演算法等演算法可以有望降低算力成本
知识蒸馏等演算法可以解决模型臃肿和算力要求过高等问题。蒸馏演算法是指将知识丰富但是臃肿的「教师网路」经过精准转换将特定领域 的知识传授给「学生网路」以实现网路结构的轻量化。知识蒸馏背後的原理是:绿色是教师网路求解空间,蓝色是学生网 络求解空间。红色为教师网路的答案空间,浅绿色为学生网路的答案空间,橙色是在知识蒸馏的情况下得到的答案空间也是最优解,如 果不加以引导(无监督训练),最後找到浅绿色的答案,而加入教师网路後,教师会给予学生指导,让学生网路得到更为准确的答案, 所以知识蒸馏会得到更加精简且效果更好的模型。
05、商业模式:开启订阅制收费,不断开放API介面
5.1、开启SaaS订阅服务,商业化变现不断打开
北京时间3月2日,OpenAI宣布以收费形式对外部公司提供API接入ChatGPT和Whisper模型的服务。API(Application Programming Interface)即应用程序介面,可以通过调用被外部使用,意味着ChatGPT和Whisper可以接入外部公司的各类软体。新发布的ChatGPT模 型和之前提供的ChatGPT产品所使用的模型均为GPT-3.5,但是其收费标准比之前的产品便宜90%,为$0.002/1k tokens。Whisper是2022 年9月OpenAI推出的语音转文本模型,现在通过API推出V2版本,并以$0.006/min进行收费。根据OpenAI官网介绍,截至3月2日,共有5 家公司接入ChatGPT API,分别是Snapchat母公司Snap Inc、全球学习平台Quizlet、日用百货配送公司Instacart、电子商务软体开发 商Shopify以及教育软体公司Speak。
5.2、订阅、API许可费和微软的深度合作是OpenAI主要收入渠道
订阅、API许可费和微软的深度合作产生的商业化收入是OpenAI目前主要的收入渠道。在订阅渠道,ChatGPT已经推出付费版本ChatGPT plus每月收费20美元,用於提升软体服务质量以及後续开发成本;在API许可费方面,OpenAI刚刚开放API介面,主要希望吸引B端用户, 一方面由於C端用户的问题杂乱且无序,所以其算力成本要高过B端用户9倍,OpenAI此举既可以吸引更多的B端用户迅速抢占市场份额以 应对生成式AI激烈的竞争环境,另一方面还可以寻求降低算力成本的途径;与微软的深度合作收入更多属於营业外收入,自2019年开始, 微软合计投入超过130亿美元,用於OpenAI的研发工作,以占领更多的云计算和搜索引擎市场。
开启API後,OpenAI将以0.002美元的价格提供1000个token,比之前版本便宜90%。成本下降後有助於推动ChatGPT与B端C端应用加速结 合,实现产品加速落地,例如结合新版Bing以及嵌入Office相关应用。 基於GPT模型收取费用已有成功案例。例如AI创作公司Jasper其商业模式是以类SAAS服务的形式进行收费,大致分为初级、高级和订制 三个模式。2021年、2022年营收分别为4000万美元、7500万美元,2022年10月,Jasper获1.25亿美元A轮融资,估值达15亿美元。此外 AI辅助编程工具Copilot在2022年6月开始收费後首月边拥有40万订阅人数,用户付费率达1/3,远超行业均值。
2021年全球云计算市场规模已突破3000亿美元。2021年全球云计算市场规模达到3307亿美元,同比增长32.44%,市场空间广阔,保持稳 定增长。按照业务划分基础服务,平台服务以及软体服务分别占27.70%、26.28%和46.02%。 OpenAI与微软的深度合作主要瞄准云计算和搜索引擎市场。微软投资OpenAI主要还是针对其主要竞争对手进行布局:一方面加强Azure 云计算领域的竞争力来对抗亚马逊,另一方面,根据StatCounter,2022年6月全球搜索引擎市场份额谷歌占据91.88%,微软有望利用 GPT模型集成到公司旗下的搜索引擎必应,打破谷歌在搜索方面的垄断地位。
06、应用场景:GPT走向多模态,下游应用场景不断打开
6.1、GPT的多模态化筑基AI多元应用
多模态指的是多种模态的信息,包括:文本、图像、视频、音频等。多模态研究的就是这些不同类型的数据的融合的问题,例如通过NLP的 预训练模型,可以得到文本的嵌入表示;再结合图像和视觉领域的预训练模型,可以得到图像的嵌入表示。 OpenAI宣称GPT-4可以接受图像和文本输入,是目前较先进的多模态大模型。ChatGPT仅可以接受文本信息的输入,而GPT-4在接收到文本和 图片的融合信息後,模型可以输出纯文本信息,包括但不限於自然语言以及代码,且具备与接受纯文本信息後相同的输出能力。除此之外, GPT-4更加具有创造性,可以生成、编辑并与用户一起迭代创造性和技术性的写作任务,例如写歌、写剧本或学惯用户的写作风格;能够处 理超过25000个单词的文本,允许使用长格式内容创建、扩展对话以及文档搜索和分析等用例。
6.2、B端应用——办公软体之Copilot
2023年3月16日,微软发布了AI服务Microsoft 365 Copilot。微软将其嵌入Word、PowerPoint、Excel 等Office 办公软体中,同时将GPT-4 模型集成至产品当中,并结合其业务数据。目前微软正在与约20家企业用户测试新产品功能。 Copilot主要通过两种方式集成到Microsoft 365中。一、直接被内置於Word、PowerPoint、Excel 等Office 办公软体中,以聊天机器人的 形式呈现在办公软体的侧边栏上;二、通过最新产品Business Chat使用,该软体被应用於大型语言模型、Microsoft 365应用以及用户的日 历、电子邮件、聊天、文档、会议和联系人,只需用户对其使用自然语言命令,便可根据会议、电子邮件和聊天记录等生成状态更新。
6.3、C端应用——聊天社交之Snapchat
Snapchat是一款「阅後即焚」照片分享应用。利用该应用程序,用户可以拍照录制视频添加文字和图画,目前在全球已经拥有7.5亿月活跃 用户。 2023年2月27日,Snapchat推出一款由OpenAI最新版ChatGPT提供支持的聊天机器人。目前正在ChatGPT API上运行,其主要功能是为用户创 建一个友好且支持自定义聊天的机器人,可以提供推荐、诗歌创作等功能。据Snapchat CEO宣称,目前阶段用户只有支付每月3.99美元,成 为付费订阅用户才可以使用具有ChatGPT支持的SnapchatPLUS,但其最终目的是将该应用服务於全体Snapchat7.5亿用户。
Quizlet是全球学习平台,日前接入ChatGPT API将推出自适应AI导师。Quizlet是一个有超过6000万学生的全球学习平台,在过去三年中一 直与OpenAI合作,包括辞汇学习和实践测试。随着ChatGPT API的推出,Quizlet将推出Q-Chat,这是一款完全自适应的AI导师,它让学生根 据通过有趣的聊天体验提供的相关学习材料提出个性化定制问题。 Speak是一款AI学习软体,由Whisper API提供支持服务。Speak是韩国增长最快的英语应用程序,已经在使用Whisper API为产品提供支持, 可为各个级别的语言学习者提供了人性化的准确性,开启开放式对话练习和高度准确的反馈,并计划推广至全世界范围
报告节选:























































(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
精选报告来源:【未来智库】「链接」
喜欢这篇文章吗?立刻分享出去让更多人知道吧!
本站内容充实丰富,博大精深,小编精选每日热门资讯,随时更新,点击「抢先收到最新资讯」浏览吧!
请您继续阅读更多来自 未来智库 的精彩文章:
※白酒行业专题报告:通胀期间白酒表现复盘,量稳利增,不惧通胀
※宠物行业专题报告:後疫情时代,宠物赛道长坡厚雪
